
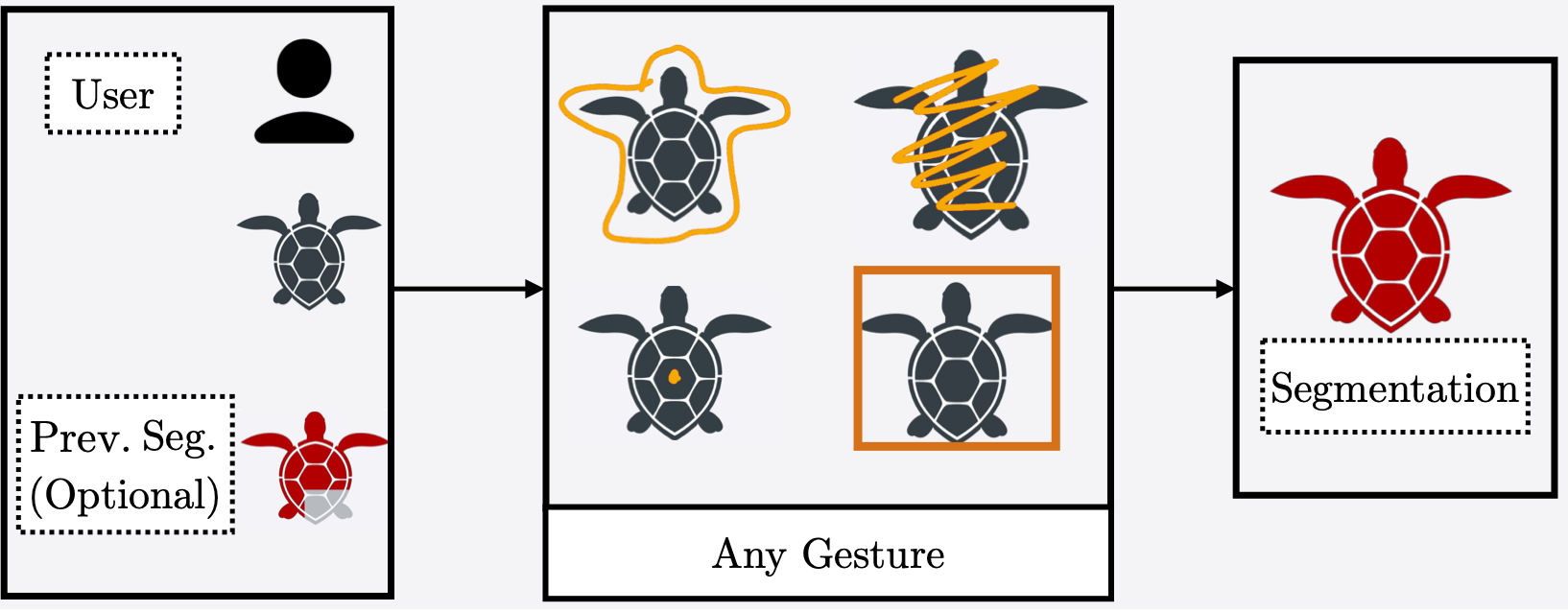
We reframe the interactive segmentation task such that algorithms only accept a marking from a user. Under our new task algorithms do not need to know the tool a user is using (e.g., scribbles, clicks) or what the context of an interaction is (i.e., either adding or subtracting content).
Interactive segmentation entails a human marking an image to guide how a model either creates or edits a segmentation. Our work addresses limitations of existing methods: they either only support one gesture type for marking an image (eg, either clicks or scribbles) or require knowledge of the gesture type being employed, and require specifying whether marked regions should be included versus excluded in the final segmentation. We instead propose a simplified interactive segmentation task where a user only must mark an image, where the input can be of any gesture type without specifying the gesture type. We support this new task by introducing the first interactive segmentation dataset with multiple gesture types as well as a new evaluation metric capable of holistically evaluating interactive segmentation algorithms. We then analyze numerous interactive segmentation algorithms, including ones adapted for our novel task. While we observe promising performance overall, we also highlight areas for future improvement. To facilitate further extensions of this work, we publicly share our new dataset at https://github. com/joshmyersdean/dig.
@InProceedings{Myers-Dean_2024_WACV,
author = {Myers-Dean, Josh and Fan, Yifei and Price, Brian and Chan, Wilson and Gurari, Danna},
title = {Interactive Segmentation for Diverse Gesture Types Without Context},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {7198-7208}
}